网页编辑与网站编辑百度信息流推广
numpy模块的loadtxt()函数用于快速读取简单格式文件的内容,常用于csv文件的读取。
1 loadtxt()函数的格式
loadtxt()函数的格式如图1所示,该函数的返回值是读取到的数据,其类型为numpy.ndarray。

图1 loadtxt()函数的格式
其中,fname表示文件的路径,其它参数均为可选参数。
2 loadtxt()函数的基本用法
在D盘根目录下有一个名为“1.csv”的文件,其内容如图2所示。
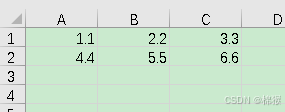
图2 “1.csv”的内容
通过loadtxt()函数读取该文件内容的代码如图3所示。

图3 通过loadtxt()函数读取该文件内容的代码
其中,loadtxt()函数的第一个参数表示文件的路径;第二个参数delimiter表示读取到内容的分隔符,因为csv文件使用逗号对数据进行分隔的,因此该参数的值是“,”。data是numpy.ndarray类型的数据。
3 loadtxt()函数的扩展用法
3.1 指定数据类型
通过loadtxt()函数的dtype参数指定读取到的数据类型,该参数默认值是float,即浮点型。
3.1.1 指定相同的数据类型
图4所示代码将读出的数据指定为相同的数据类型。
图4 将读出的数据指定为相同的数据类型的代码
其中,将dtype的值设置为int,表示将所有的数据都指定为整型,此时会有图4所示的红色字体的警告,表示将float转换为int会有数据不精确的情况。
3.1.2 指定不同的数据类型
图5所示代码将读出的数据指定为不同的数据类型。

图5 将读出的数据指定为不同的数据类型的代码
其中,参数dtype用字典进行赋值,该字典中第一个键值对表示读出的散列数据的名称,第二个键值对表示读出的三列数据的类型,分别是字符串、整型和浮点型。
3.2 忽略指定行数
通过图6所示代码忽略文件中指定的行数。

图6 忽略文件中指定的行数的代码
其中,当参数skiprows=1时,表示忽略数据中的第1行;当参数skiprows=2时,表示忽略数据中的第1-2行,因为此时没有读取数据,因此程序会有红色字体的警告。
3.3指定要读取的列
通过图7所示代码指定要读取的列。

图7 指定要读取列的代码
其中,参数usecols指定了要读取的列,该参数的类型是元组,其元素为对应的列,0和2表示读取第1列和第3列的数据。
3.4 对数据进行预处理
通过图8所示代码对读取到的数据进行预处理。

图8 对读取到的数据进行预处理的代码
其中,func()是自定义函数,参数convereters的值是一个字典,该字典的键表示列数,值表示对该列数据进行的预处理。以上代码表示对第2列的数据进行×2的预处理。
3.5 对数据进行解包
通过图9所示代码对读取到的数据进行解包。

图9 对读取到的数据进行解包的代码
其中,参数unpack的值设置为True,对读取到的数据按行进行解包,分别保存到data1、data2和data3中。