seo网站设计点击软件如何做好推广
在neo4j中创建结点和关系
创建结点
创建电影结点
例如:创建一个Movie结点,这个结点上带有三个属性{title:‘The Matrix’, released:1999, tagline:‘Welcome to the Real World’}
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
创建人物结点
例如:创建一个Person节点,结点带有两个属性:{name:‘Keanu Reeves’, born:1964}。
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
创建关系
创建人物之间的关系的语句使用了箭头运算符。例如:(Keanu)-[:ACTED_IN {roles:[‘Neo’]}]->(TheMatrix)语句表示创建一个演员参演电影的关系,演员Keanu以角色Neo参演ACTED_IN了电影TheMatrix。
创建人物之间的关系
CREATE(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),(LillyW)-[:DIRECTED]->(TheMatrix),(LanaW)-[:DIRECTED]->(TheMatrix),(JoelS)-[:PRODUCED]->(TheMatrix)
使用python语言操作neo4j数据库
对于python开发者来说,Py2neo库可以完成对neo4j的操作。
首先安装Py2neo,建立数据库连接。Py2neo使用pip安装:
pip install py2neo
连接数据库
建立连接代码示例:定义movie_db为待使用的neo4j连接[默认的账号密码均为“neo4j”,若已修改则为新的,我的密码已修改为“12345678”]
# Graph("http://127.0.0.1:7474",auth=("账号","密码"))
import py2neo
Movie_db=Graph("http://localhost:7474",auth=("neo4j","12345678"))
后续添加结点时可能会报错,== Cannot decode response content as JSON ==
此时只需要将连接语句修改为:即指定连接数据库name=‘neo4j’
Movie_db=Graph("http://localhost:7474",auth=("neo4j","12345678"),name='neo4j')
建立结点、关系
建立结点时候要定义结点的标签和一些基本属性。
Node:节点
基本语法:
node_1=Node(*labels,**properties)
Movie_db.create(node_1)
注意:代码中,test_graph.create(node_1)的作用是将本地创建的node放入数据库中,后面关系、路径等,在本地创建以后,均需要create。
node_1 = Node('英雄',name = '张无忌')
node_2 = Node('英雄',name = '杨逍',武力值='100')
node_3 = Node('派别',name = '明教')# 存入图数据库
test_graph.create(node_1)
test_graph.create(node_2)
test_graph.create(node_3)
print(node_1)
Relationship:关系
基本语法:
Relationship((start_node, type, end_node, **properties))
例如建立两个测试的结点:
test_node_1 = Node(label = "person",name="test_node_1")# 头实体
test_node_2 = Node(label = "movie",name ="test_node_2")# 尾实体
#Movie_db.create(test_node_2)#建立尾结点# 关系
relation = Relationship(test_node_1, "DIRECTED", test_node_2)
# 创建关系(连带创建节点)
Movie_db.create(relation)表示创建两个结点关系为test_node_1导演了,test_node_2。需要注意的是,如果建立关系的时候起始结点不存在,则建立关系的同时会建立这个结点。
Path:路径
基本语法:
Path(*entities)
注意entities是实体(关系,节点都可以作为实体)。
例如
from py2neo import Path
# 建一个路径:比如按照该路径查询,或者遍历的结果保存为路径
node_4,node_5,node_6 = Node(name='阿大'),Node(name='阿二'),Node(name='阿三')
path_1 = Path(node_4,'小弟',node_5,Relationship(node_6, "小弟", node_5),node_6)
Movie_db.create(path_1)print(path_1)
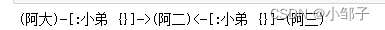
* Subgraph:子图
子图是节点和关系的任意集合,它也是 Node、Relationship 和 Path 的基类。
基本语法:
Subgraph(nodes, relationships)
空子图表示为None,使用bool()可以测试是否为空。参数要按数组输入,如下面代码。
# 创建一个子图,并通过子图的方式更新数据库
node_1 = Node('英雄',name = '张无忌')
node_7 = Node('英雄',name = '张翠山')
node_8 = Node('英雄',name = '殷素素')
node_9 = Node('英雄',name = '狮王')relationship7 = Relationship(node_1,'生父',node_7)
relationship8 = Relationship(node_1,'生母',node_8)
relationship9 = Relationship(node_1,'义父',node_9)
subgraph_1 = Subgraph(nodes = [node_7,node_8,node_9],relationships = [relationship7,relationship8,relationship9])
Movie_db.create(subgraph_1)删除结点
删除数据库中所有节点和关系:
Movie_db.delete_all()
其他删除方法如下(删除的基础是查询,但凡查询条件没错,就不会删错):
# 删除所有:谨慎使用
# Movie_db.delete_all()# 按照节点id删除:要删除某个节点之前,需要先删除关系。否则会报错:ClientError
Movie_db.run('match (r) where id(r) = 3 delete r')
# 按照name属性删除:先增加一个单独的节点:
node_x = Node('英雄',name ='韦一笑')
Movie_db.create(node_x)
Movie_db.run('match (n:英雄{name:\'韦一笑\'}) delete n')# 删除一个节点及与之相连的关系
Movie_db.run('match (n:英雄{name:\'韦一笑\'}) detach delete n')
# 删除某一类型的关系
Movie_db.run('match ()-[r:喜欢]->() delete r;')# 删除子图
# delete(self, subgraph)
修改结点
改的基础也是查询,查到就可以改,因此本文的重点放在查询上,下面示例简单修改。
# 改
# 将狮王的武力值改为100
node_9['武力值']=100
# 本地修改完,要push到服务器上哦
Movie_db.push(node_9)
查询结点
Movie_db的nodes属性包含图当中的所有节点信息,请查考下面代码:
for node in Movie_db.nodes:print(node)
也可以使用match方法来找到相应节点,请参考以下代码:
n=Movie_db.nodes.match("Person")
for i in n:print(i)

当然也可以进行更为细致的匹配,请参考以下代码
n=Movie_db.nodes.match("Person",name='Keanu Reeves')
for i in n:print(i)
NodeMatcher
NodeMatcher:定位满足特定条件的节点。
基本语法:
NodeMatcher(graph).match(*labels, **properties)
结合不同的方法可以取得不同的效果。主要方法表如下所示:
| 方法名 | 功能 |
|---|---|
| first() | 返回查询结果第一个Node,没有则返回空 |
| all() | 返回所有节点 |
| where(condition,properties) | 对查询结果二次过滤 |
| order_by | 排序 |
# 定义查询
nodes = NodeMatcher(Movie_db)# 单个节点,按照label和name查询
## 查询节点:狮王
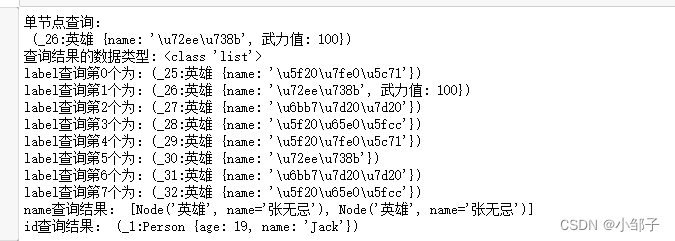
node_single = nodes.match("英雄", name="狮王").first()
print('单节点查询:\n',node_single )## 按照label查询所有节点
node_hero = nodes.match("英雄").all()
print('查询结果的数据类型:',type(node_hero))# 在查询结果中循环取值,用first()取出第一个值
i = 0
for node in node_hero:print('label查询第{}个为:{}'.format(i,node))i+=1## 按照name查询所有节点:用all()取出所有值
node_name = nodes.match(name='张无忌').all()
print('name查询结果:',node_name)# get()方法按照id查询节点
node_id = nodes.get(1)
print('id查询结果:',node_id)
NodeMatch
NodeMatch:基本用法,
NodeMatch(graph, labels=frozenset({}), predicates=(), order_by=(), skip=None, limit=None)
可以看出,NodeMatch的参数和NodeMatcher的参数完全不同。后面是可以加很多条件的,包含的主要方法如下表:
| 方法 | 作用 |
|---|---|
| iter(match) | 遍历所匹配节点 |
| len(match) | 返回匹配到的节点个数 |
| all() | 返回所有节点 |
| count() | 返回节点计数,评估所选择的节点 |
| limit(amount)、 返回节点的最大个数 | |
| order_by(*fields) | 按指定的字段或字段表达式排序。要引用字段或字段表达式中的当前节点,请使用下划线字符 |
| where(*predicates, **properties) | 二次过滤 |
from py2neo import NodeMatch
nodess = NodeMatch(Movie_db,labels=frozenset({'英雄'}))
# 遍历查询到的节点
print('='*15,'遍历所有节点','='*15)
for node in iter(nodess):print(node)
# 查询结果计数
print('='*15,'查询结果计数','='*15)
print(nodess.count())
# 按照武力值排序查询结果:注意引用字段的方式,前面要加下划线和点:_.武力值
print('='*10,'按照武力值排序查询结果','='*10)
wu = nodess.order_by('_.武力值')
for i in wu:print(i)RelationshipMatcher
RelationshipMatcher:用于选择满足一组特定标准的关系的匹配器。
基础语法:
relation = RelationshipMatcher(Movie_db)
from py2neo import RelationshipMatcher
# 查询某条关系
relation = RelationshipMatcher(Movie_db)# None表示any node哦!不是表示空
print('='*10,'hate关系查询结果','='*10)
x = relation.match(nodes=None, r_type='hate')
for x_ in x:print(x_)
# 增加俩关系
re1_1 = Relationship(node_101,'情敌',node_102)
re1_2 = Relationship(node_102,'情敌',node_103)
test_graph.create(re1_1)
test_graph.create(re1_2)
# 情敌查询结果
print('='*10,'hate关系查询结果','='*10)
x = relation.match(nodes=None, r_type='情敌')
for x_ in x:print(x_)RelationshipMatch
基本语法:
RelationshipMatch(graph, nodes=None, r_type=None, predicates=(), order_by=(), skip=None, limit=None)
可以按照NodeMatch理解
参考
https://zhuanlan.zhihu.com/p/437824721