酒店网站建设协议seo教程之关键词是什么
目录
Windows selenium配置
下载地址
Chrome Chromedriver 版本对应关系
实践测试
操作元素
浏览器操作
获取元素信息
鼠标操作
实战demo
selenium添加代理
Linux selenium配置
检查服务器环境
下载安装第三方库(最简单版)
实践测试
代码测试
目录下生成截图 png 查看
让 Selenium 在 Linux 中以有头模式运行
Xvfb介绍
实战测试
Windows selenium配置
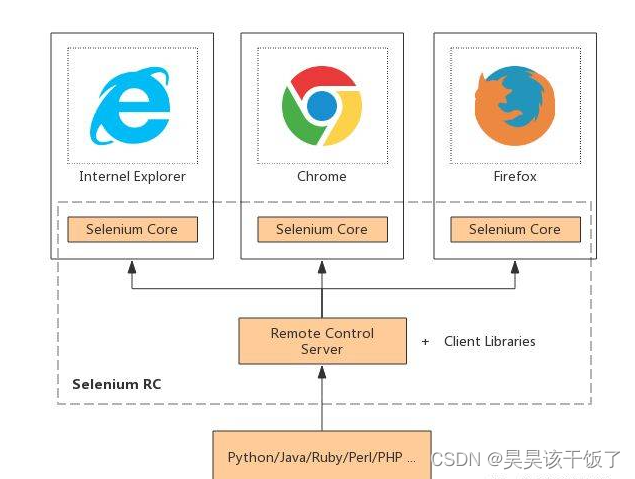
下载地址(大佬直接点就好)
Selenium
ChromeDriver
Chrome
GeckoDriver
Firefox
Chrome Chromedriver 版本对应关系
我们维护多个版本的ChromeDriver。选择哪个版本取决于您所使用的Chrome浏览器的版本。
- 具体来说,ChromeDriver使用与Chrome相同的版本号方案。更多详情请参见https://www.chromium.org/developers/version-numbers。
- 每个版本的ChromeDriver都支持Chrome,其主要版本号、次要版本号和构建版本号都是一致的。例如,ChromeDriver 73.0.3683.20支持所有以73.0.3683开头的Chrome版本。
- 在新的Chrome大版本进入Beta版之前,会发布一个匹配的ChromeDriver版本。
- 在新的主要版本首次发布后,我们将根据需要发布补丁。这些补丁可能与Chrome浏览器的更新相吻合,也可能不吻合。
以下是选择下载ChromeDriver版本的步骤:
- 首先,找出您正在使用的Chrome浏览器的版本。比方说,你的Chrome是72.0.3626.81。
- 取出Chrome浏览器的版本号,去掉最后一部分,然后将结果附加到URL "https://chromedriver.storage.googleapis.com/LATEST_RELEASE_"上。例如,使用Chrome浏览器的版本为72.0.3626.81,你会得到一个URL “https://chromedriver.storage.googleapis.com/LATEST_RELEASE_72.0.3626”。
- 使用最后一步创建的URL来检索一个包含要使用的ChromeDriver版本的小文件。例如,上述URL将得到一个包含 "72.0.3626.69 "的文件。(当然,实际数字在未来可能会发生变化)。
- 使用从上一步骤中获取的版本号来构建下载ChromeDriver的URL。如果是72.0.3626.69版本,URL将是 “https://chromedriver.storage.googleapis.com/index.html?path=72.0.3626.69/”。
- 初次下载后,建议你偶尔再走一遍上述流程,看看是否有任何错误修复版本。
实践测试
操作元素
1、.send_keys() # 输入方法
2、.click() # 点击方法
3、.clear() # 清空方法浏览器操作
1、driver.maximize_window() # 最大化浏览器
2、driver.set_window_size(w,h) # 设置浏览器大小 单位像素 【了解】
3、driver.set_window_position(x,y) # 设置浏览器位置 【了解】
4、driver.back() # 后退操作
5、driver.forward() # 前进操作
6、driver.refrensh() # 刷新操作
7、driver.close() # 关闭当前主窗口(主窗口:默认启动那个界面,就是主窗口)
8、driver.quit() # 关闭driver对象启动的全部页面
9、driver.title # 获取当前页面title信息
10、driver.current_url # 获取当前页面url信息获取元素信息
1、text 获取元素的文本; 如:driver.text
2、size 获取元素的大小: 如:driver.size
3、get_attribute 获取元素属性值;如:driver.get_attribute("id") ,传递的参数是元素的属性名
4、is_displayed 判断元素是否可见 如:element.is_displayed()
5、is_enabled 判断元素是否可用 如:element.is_enabled()
6、is_selected 判断元素是否被选中 如:element.is_selected()鼠标操作
1、context_click(element) # 右击
2、double_click(element) #双击
3、double_and_drop(source, target) # 拖拽
4、move_to_element(element) # 悬停 【重点】
5、perform() # 执行以上事件的方法 【重点】实战demo
# demo
from selenium import webdriver
from selenium.webdriver.common.by import By
import timeoptions = webdriver.ChromeOptions()options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
options.add_argument('--disable-dev-shm-usage')
# options.add_argument('--proxy-server=http://{0}'.format(ip))
driver = webdriver.Chrome(options=options)# 用户正常访问该值为false。使用selenium时该值为true。
# 下面代码解决掉这个问题
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""
})
driver.get("https://www.baidu.com/")
time.sleep(5)
# 截图看是否访问了百度
driver.save_screenshot("baidu.png")selenium添加代理
做爬虫怎么也要用到代理是吧,即使是自动化也不可能一个ip地址一天访问几千上万
# 添加无认证代理,以参数形式添加
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument('--proxy-server=http://ip:port')
driver = webdriver.Chrome(chrome_options=chromeOptions)无认证代理的话如果没有可以给大家分享一个用户服务中心,可以提供api接口直接拿,现在好像是免费测试试用七天。
Linux selenium配置
检查服务器环境
[root@aa /]# lsb_release -a
Distributor ID: CentOS
Release: 7.9.2009[root@aa /]# python -V
Python 2.7.5[root@aa /]# python3 -V
Python 3.6.8下载安装第三方库(最简单版)
# 安装selenium
pip3 install selenium
# 安装chromedriver
yum install https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm yum install mesa-libOSMesa-devel gnu-free-sans-fonts wqy-zenhei-fonts
# 下载对应版本Chromedriver(没输错就是下面这个版本对应的网址) https://chromedriver.storage.googleapis.com/index.html?path=110.0.5481.30/
# 移动位置
mv chromedriver /usr/bin/
# 给予执行权限
chmod +x /usr/bin/chromedriver
实践测试
代码测试
# demo
from selenium import webdriver
from selenium.webdriver.common.by import By
import time#options = webdriver.ChromeOptions()
#options.add_argument('--headless')
options = webdriver.ChromeOptions()
# 服务器无界面运行,否则会报错,后续配置插件解决
options.add_argument("headless")options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
options.add_argument('--disable-dev-shm-usage')
# options.add_argument('--proxy-server=http://{0}'.format(ip))
driver = webdriver.Chrome(options=options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""
})
driver.get("https://www.baidu.com/")
time.sleep(5)
# 截图看是否访问了百度
driver.save_screenshot("aaaaaaaaaaaaaaaaaa.png")目录下生成截图 png 查看
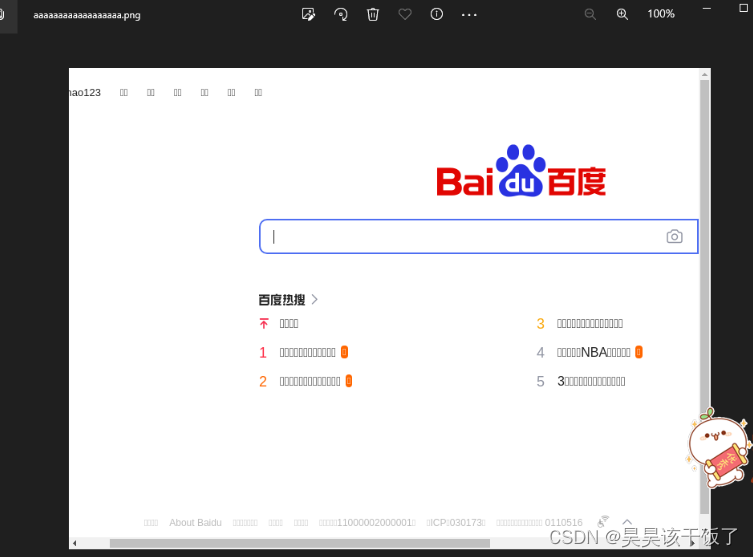
让 Selenium 在 Linux 中以有头模式运行
Xvfb介绍
Xvfb 在一个没有图像设备的机器上实现了 X11显示服务的协议,它实现了其他图形界面都有的各种接口,但并没有真正的图形界面
所以当一个程序在 Xvfb 中调用图形界面相关的操作时,这些操作都会在虚拟内存里面运行,只不过你什么都看不到而已
使用 Xvfb,我们就可以欺骗 Selenium 或者 Puppeteer,让它以为自己运行在一个有图形界面的系统里面,这样一来就能够正常使用有头模式了
# 安装
yum install Xvfb
实战测试
# 更改 demo# 服务器无界面运行,否则会报错,后续配置插件解决
# 注释掉 以正常有界面模式运行
# options.add_argument("headless")xvfb-run XXX
# 例如
xvfb-run python3 selenium_test.py运行查看截图 成功
----------
2023.2.20