自动做设计的网站刷seo排名
目录
1、前言
2、 完整代码
3、运行过程+结果
4、遇到的问题
5、小结
- 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
1、前言
这周主要是使用VGG16模型,完成明星照片识别。
2、 完整代码
from keras.utils import losses_utils
from tensorflow import keras
from keras import layers, models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from keras.callbacks import ModelCheckpoint, EarlyStoppinggpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0], "GPU")# 导入数据
data_dir = "/Users/MsLiang/Documents/mySelf_project/pythonProject_pytorch/learn_demo/P_model/p06_vgg16/data"
data_dir = pathlib.Path(data_dir)# 查看数据
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count) # 1800roses = list(data_dir.glob('Jennifer Lawrence/*.jpg'))
img = PIL.Image.open(str(roses[0]))
# img.show() # 查看图片# 数据预处理
# 1、加载数据
batch_size = 32
img_height = 224
img_width = 224print('data_dir======>',data_dir)
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.1,subset="training",label_mode="categorical",seed=123,image_size=(img_height, img_width),batch_size=batch_size)"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.1,subset="validation",label_mode="categorical",seed=123,image_size=(img_height, img_width),batch_size=batch_size)class_names = train_ds.class_names
print(class_names)# 可视化数据
plt.figure(figsize=(20, 10))for images, labels in train_ds.take(1):for i in range(20):ax = plt.subplot(5, 10, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[np.argmax(labels[i])])plt.axis("off")
plt.show()# 再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape) # (32, 224, 224, 3)print(labels_batch.shape) # (32, 17)break# 配置数据集
AUTOTUNE = tf.data.AUTOTUNEtrain_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)# 构建CNN网络
"""
关于卷积核的计算不懂的可以参考文章:https://blog.csdn.net/qq_38251616/article/details/114278995layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/115826689
"""model = models.Sequential([keras.layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=(img_height, img_width, 3)),layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样layers.Dropout(0.5),layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.AveragePooling2D((2, 2)),layers.Dropout(0.5),layers.Conv2D(128, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.Dropout(0.5),layers.Flatten(), # Flatten层,连接卷积层与全连接层layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取layers.Dense(len(class_names)) # 输出层,输出预期结果
])# model.summary() # 打印网络结构# 训练模型
# 1、设置动态学习率
# 设置初始学习率
initial_learning_rate = 1e-4lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate,decay_steps=60, # 敲黑板!!!这里是指 steps,不是指epochsdecay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lrstaircase=True)# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)model.compile(optimizer=optimizer,loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 损失函数
# 调用方式1:
model.compile(optimizer="adam",loss='categorical_crossentropy',metrics=['accuracy'])# 调用方式2:
# model.compile(optimizer="adam",
# loss=tf.keras.losses.CategoricalCrossentropy(),
# metrics=['accuracy'])# sparse_categorical_crossentropy(稀疏性多分类的对数损失函数)
# 调用方式1:
model.compile(optimizer="adam",loss='categorical_crossentropy',metrics=['accuracy'])
# ↑↑↑↑这里出现报错,需要将 sparse_categorical_crossentropy 改成→ categorical_crossentropy↑↑
# 调用方式2:
# model.compile(optimizer="adam",
# loss=tf.keras.losses.SparseCategoricalCrossentropy(),
# metrics=['accuracy'])# 函数原型
tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False,reduction=losses_utils.ReductionV2.AUTO,name='sparse_categorical_crossentropy'
)epochs = 100# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',monitor='val_accuracy',verbose=1,save_best_only=True,save_weights_only=True)# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',min_delta=0.001,patience=20,verbose=1)# 网络模型训练
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,callbacks=[checkpointer, earlystopper])# 模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(len(loss))plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()# 指定图片进行预测
# 加载效果最好的模型权重
model.load_weights('best_model.h5')from PIL import Image
import numpy as npimg = Image.open("/Users/MsLiang/Documents/mySelf_project/pythonProject_pytorch/learn_demo/P_model/p06_vgg16/data/Jennifer Lawrence/003_963a3627.jpg") #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])img_array = tf.expand_dims(image, 0)predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])3、运行过程+结果
【查看图片】

【模型运行过程---第21epoch就早停了】
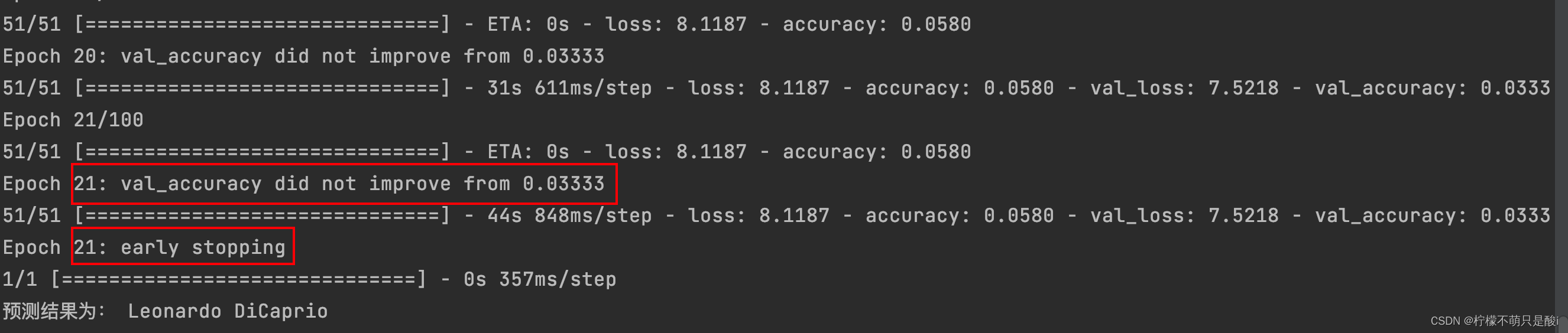
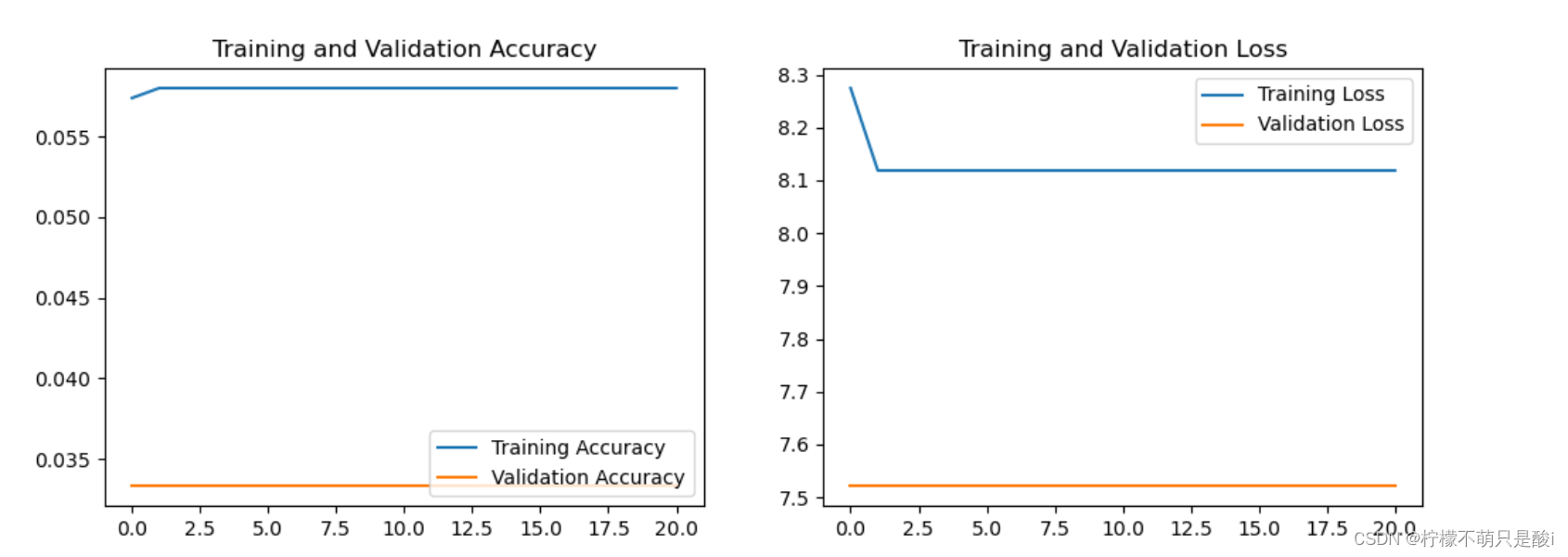
【训练精度、损失-----显然结果很很差】
4、遇到的问题
① 在运行代码的时候遇到报错:
错误:Graph execution error: Detected at node 'sparse_categorical_crossentropy/SparseSoftmaxCrossEntropyWithLogits/SparseSoftmaxCrossEntropyWithLogits' defined at (most recent call last):
出现这个问题来自我们使用的损失函数。
model.compile(optimizer="adam",loss='sparse_categorical_crossentropy',metrics=['accuracy'])解决办法:
将损失函数里面的loss='sparse_categorical_crossentropy' 改成 'categorical_crossentropy',即可解决报错问题。
关于sparse_categorical_crossentropy和categorical_crossentropy的更多细节,详细参考这篇博文:交叉熵损失_多分类交叉熵损失函数-CSDN博客
5、小结
原始模型,跑出来效果很差很差!!!
(1)将原来的Adam优化器换成SGD优化器,效果如下:
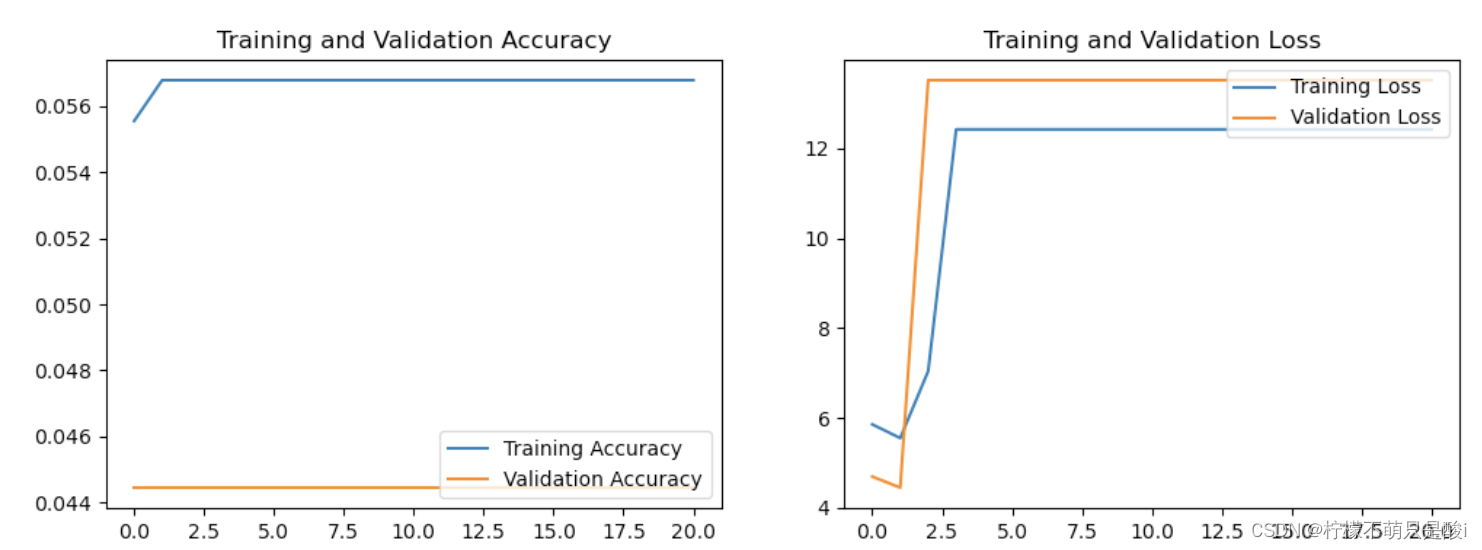
(2)后续再补充,最近在写结课论文,有些忙。